生のSQLを使ってデータベースのレコードを検索することに慣れた人がRailsに出会うと、Railsでは同じ操作をずっと洗練された方法で実現できることに気付くでしょう。Active Recordを使うことで、SQLを直に実行する必要はほぼなくなります。
Active Recordは、ユーザーに代わってデータベースにクエリを発行します。発行されるクエリは多くのデータベースシステム(MySQL、MariaDB、PostgreSQL、SQLiteなど)と互換性があります。Active Recordを使えば、利用しているデータベースシステムの種類にかかわらず同じ記法を使えます。
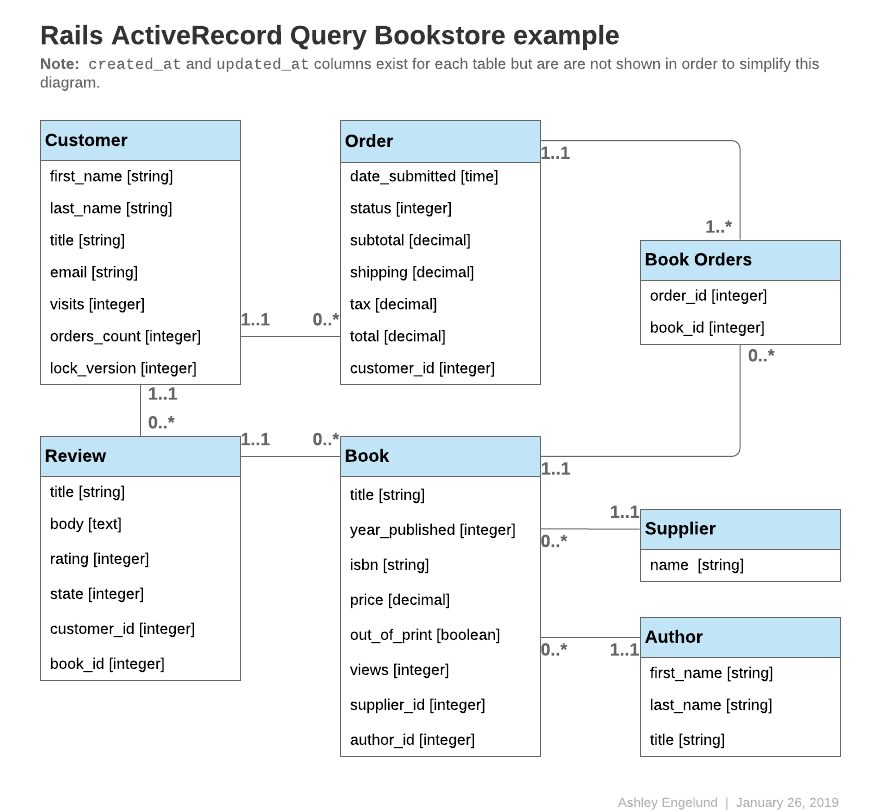
本ガイドのコード例では以下のモデルを使います。
特に記さない限り、モデル中のidは主キーを表します。
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where('year_published < ?', 50.years.ago )}
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum status: [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where('created_at < ?', time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum state: [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
Active Recordでは、データベースからオブジェクトを取り出すための検索メソッドを多数用意しています。これらの検索メソッドを利用することで、生のSQLを書かずにデータベースへの特定のクエリを実行するための引数を渡せるようになります。
以下のメソッドが用意されています。
検索メソッドにはwhereやgroupといったコレクションを返すものもあれば、ActiveRecord::Relationインスタンスを返すものもあります。また、findやfirstなど1件のエンティティを検索するメソッドの場合、そのモデルの単一のインスタンスを返します。
Model.find(options)という操作を要約すると以下のようになります。
- 与えられたオプションを同等のSQLクエリに変換します。
- SQLクエリを発行し、該当する結果をデータベースから取り出します。
- 得られた結果を行ごとに同等のRubyオブジェクトとしてインスタンス化します。
- 指定されていれば、
after_findを実行し、続いてafter_initializeコールバックを実行します。
Active Recordには、単一のオブジェクトを取り出すためのさまざま方法が用意されています。
findメソッドを使うと、与えられたどのオプションにもマッチする「主キー」に対応するオブジェクトを取り出せます。以下に例を示します。
# 主キー(id)が10のクライアントを検索
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
これと同等のSQLは以下のようになります。
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
findメソッドでマッチするレコードが見つからない場合、ActiveRecord::RecordNotFound例外が発生します。
このメソッドを使って、複数のオブジェクトへのクエリを作成することもできます。これを行うには、findメソッドの呼び出し時に主キーの配列を渡します。これにより、指定の「主キー」にマッチするレコードをすべて含む配列が返されます。以下に例を示します。
# 主キー(id)が1と10のクライアントを検索
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 10, first_name: "Ryan">]
これと同等のSQLは以下のようになります。
SELECT * FROM customers WHERE (customers.id IN (1,10))
findメソッドに渡された主キーの中に、どのレコードにもマッチしない主キーが1個でもあると、ActiveRecord::RecordNotFound例外が発生します。
takeメソッドはレコードを1件取り出します。どのレコードが取り出されるかは指定されません。以下に例を示します。
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
これと同等のSQLは以下のようになります。
SELECT * FROM customers LIMIT 1
Model.takeは、モデルにレコードが1つもない場合にnilを返します。このとき例外は発生しません。
以下のように、takeメソッドで返すレコードの最大数を数値の引数で指定することもできます。
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
これと同等のSQLは以下のようになります。
SELECT * FROM customers LIMIT 2
take! メソッドの動作は、マッチするレコードが見つからない場合にActiveRecord::RecordNotFound例外が発生する点を除いて、takeメソッドとまったく同じです。
このメソッドで取り出されるレコードは、利用するデータベースエンジンによって異なることがあります。
firstメソッドは、デフォルトでは主キー順の最初のレコードを取り出します。以下に例を示します。
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
これと同等のSQLは以下のようになります。
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
firstメソッドは、モデルにレコードが1件もない場合はnilを返します。このとき例外は発生しません。
デフォルトスコープが順序に関するメソッドを含んでいる場合、firstメソッドはその順序に沿って最初のレコードを返します。
以下のように、firstメソッドで返すレコードの最大数を数値の引数で指定することもできます。
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
これと同等のSQLは以下のようになります。
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
orderを使って順序を変更したコレクションの場合、firstメソッドはorderで指定された属性に従って最初のレコードを返します。
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
これと同等のSQLは以下のようになります。
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
first!メソッドの動作は、マッチするレコードが見つからない場合にActiveRecord::RecordNotFound例外が発生する点を除いて、firstメソッドとまったく同じです。
lastメソッドは、(デフォルトでは) 主キーの順序に従って最後のレコードを返します。 以下に例を示します。
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
これと同等のSQLは以下のようになります。
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
lastメソッドは、モデルにレコードが1件もない場合はnilを返します。このとき例外は発生しません。
デフォルトスコープが順序に関するメソッドを含んでいる場合、lastメソッドはその順序に従って最後のレコードを返します。
lastメソッドで返すレコードの最大数を数値の引数で指定することもできます。例:
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
これと同等のSQLは以下のようになります。
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
orderを使って順序を変更したコレクションの場合、lastメソッドはorderで指定された属性に従って最後のレコードを返します。
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
これと同等のSQLは以下のようになります。
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
last!メソッドの動作は、マッチするレコードが見つからない場合にActiveRecord::RecordNotFound例外が発生する点を除いて、lastメソッドとまったく同じです。
find_byメソッドは、与えられた条件にマッチするレコードのうち最初のレコードだけを返します。以下に例を示します。
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
上の文は以下のように書くこともできます。
Customer.where(first_name: 'Lifo').take
これと同等のSQLは以下のようになります。
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
上のSQLにORDER BYがない点にご注意ください。find_byの条件が複数のレコードにマッチする場合は、レコードの順序を一貫させるために並び順を指定すべきです。
find_by! メソッドの動作は、マッチするレコードが見つからない場合にActiveRecord::RecordNotFound例外が発生する点を除いて、find_byメソッドとまったく同じです。以下に例を示します。
irb> Customer.find_by! first_name: 'does not exist'
=> ActiveRecord::RecordNotFound
上の文は以下のように書くこともできます。
Customer.where(first_name: 'does not exist').take!
多数のレコードに対して反復処理を行いたいことがあります。たとえば、多くのユーザーにニュースレターを送信したい、データをエクスポートしたいなどです。
このような処理をそのまま実装すると以下のようになるでしょう。
# このコードはテーブルが大きい場合にメモリを大量に消費する可能性あり
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
しかし上のような処理は、テーブルのサイズが大きくなるにつれて非現実的になります。Customer.all.eachは、Active Recordに対して テーブル全体を一度に取り出し、しかも1行ごとにオブジェクトを生成し、その巨大なモデルオブジェクトの配列をメモリに配置するからです。もし莫大な数のレコードに対してこのようなコードをまともに実行すると、コレクション全体のサイズがメモリ容量を上回ってしまうことでしょう。
Railsでは、メモリを圧迫しないサイズにバッチを分割して処理するための方法を2とおり提供しています。1つ目はfind_eachメソッドを使う方法です。これは、レコードのバッチを1つ取り出してから、次に各レコードを1つのモデルとして個別にブロックにyieldします。2つ目の方法はfind_in_batchesメソッドを使う方法です。レコードのバッチを1つ取り出してから、次にバッチ全体をモデルの配列としてブロックにyieldします。
find_eachメソッドとfind_in_batchesメソッドは、一度にメモリに読み込めないような大量のレコードに対するバッチ処理のためのものです。数千件のレコードに対して単にループ処理を行なう程度なら通常の検索メソッドで十分です。
find_eachメソッドは、複数のレコードを一括で取り出し、続いて 各 レコードを1つのブロックにyieldします。以下の例では、find_eachでバッチから1000件のレコードを一括で取り出し、各レコードをブロックにyieldします。
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
この処理は、必要に応じてさらにレコードのまとまりをフェッチし、すべてのレコードが処理されるまで繰り返されます。
find_eachメソッドは上述のようにモデルのクラスに対して機能します。上で見たように、対象がリレーションの場合も同様です。
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
ただしこれは順序指定がない場合に限ります。find_eachメソッドでイテレートするには内部で順序を強制する必要があるためです。
レシーバー側に順序がある場合、config.active_record.error_on_ignored_orderフラグの状態によって振る舞いが変わります。たとえばtrueの場合はArgumentErrorが発生し、falseの場合は順序が無視されて警告が発生します。デフォルトはfalseです。このフラグを上書きしたい場合は:error_on_ignoreオプション(後述)を使います。
:batch_size
:batch_sizeオプションは、(ブロックに個別に渡される前に)1回のバッチで取り出すレコード数を指定します。たとえば、1回に5000件ずつ処理したい場合は以下のように指定します。
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
デフォルトでは、レコードは主キーの昇順に取り出されます。並び順冒頭のIDが不要な場合は、:startオプションを使ってシーケンスの開始IDを指定できます。これは、たとえば中断したバッチ処理を再開する場合などに便利です(最後に実行された処理のIDがチェックポイントとして保存済みであることが前提です)。
たとえば主キーが2000番以降のユーザーに対してニュースレターを配信する場合は、以下のようになります。
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
:startオプションと同様に、シーケンスの末尾のIDを指定したい場合は、:finishオプションで末尾のIDを設定できます。 :startと:finishでレコードのサブセットを指定し、その中でバッチプロセスを走らせたい時に便利です。
たとえば主キーが2000番〜10000番のユーザーに対してニュースレターを配信したい場合は、以下のようになります。
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
他にも、同じ処理キューを複数のワーカーで手分けする場合が考えられます。たとえばワーカーごとに10000レコードずつ処理したい場合も、:startと:finishオプションにそれぞれ適切な値を設定することで実現できます。
:error_on_ignore
リレーション内に特定の順序があれば例外を発生させたい場合は、このオプションでアプリケーションの設定を上書きします。
:order
主キーの並び順(:ascまたは:desc)を指定します。デフォルト値は:ascです。
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
find_in_batchesメソッドは、レコードをバッチで取り出すという点でfind_eachと似ています。違うのは、find_in_batchesはバッチを個別にではなくモデルの配列としてブロックにyieldするという点です。以下の例では、与えられたブロックに対して一度に最大1000人までの顧客(customer)の配列をyieldしています。最後のブロックには残りの顧客が含まれます。
# 1回あたり1000人の顧客の配列をadd_customersに渡す
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batchesメソッドは上述のようにモデルのクラスに対して機能します。対象がリレーションの場合も同様です。
# 1回あたり直近のアクティブな1000人の顧客の配列をadd_customersに渡す
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
ただしこれは順序指定がない場合に限ります。find_in_batchesメソッドでイテレートするには内部で順序を強制する必要があるためです。
find_in_batchesメソッドでは、find_eachメソッドと同様のオプションを使えます。
:batch_size
find_eachと同様に、batch_sizeはグループごとのレコード数を指定します。たとえば、レコードを2500件ずつ取り出すには以下のように指定できます。
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
startオプションを使うと、レコードがSELECTされるときの最初のIDを指定できます。上述のように、デフォルトではレコードを主キーの昇順でフェッチします。たとえば、ID: 5000から始まる顧客レコードを2500件ずつ取り出すには、以下のようなコードが使えます。
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
finishオプションを使うと、レコードを取り出すときの末尾のIDを指定できます。以下は、ID: 7000までの顧客レコードをバッチで取り出す場合のコードです。
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
リレーション内に特定の順序があれば例外を発生させたい場合は、error_on_ignoreオプションでアプリケーションの設定を上書きします。
where メソッドは、返されるレコードを制限するための条件を指定します。SQL文で言うWHEREの部分に相当します。条件は、文字列、配列、ハッシュのいずれかの方法で与えることができます。
検索メソッドに条件を追加したい場合、たとえばBook.where("title = 'Introduction to Algorithms'")のように条件を単純に指定できます。この場合、titleフィールドの値が'Introduction to Algorithms'であるすべてのクライアントが検索されます。
条件を文字列だけで構成すると、SQLインジェクションの脆弱性が発生する可能性があります。たとえば、Book.where("title LIKE '%#{params[:title]}%'")という書き方は危険です。次で説明するように、配列を使うのが望ましい方法です。
条件で使う数値が変動する可能性がある場合、引数をどのようにすればよいでしょうか。この場合は以下のようにします。
Book.where("title = ?", params[:title])
Active Recordは最初の引数を、文字列で表された条件として受け取ります。その後に続く引数は、文字列内にある疑問符 ? と置き換えられます。
複数の条件を指定したい場合は次のようにします。
Book.where("title = ? AND out_of_print = ?", params[:title], false)
上の例では、1つ目の疑問符はparams[:title]の値で置き換えられ、2つ目の疑問符はfalseをSQL形式に変換したもの (変換方法はアダプタによって異なる) で置き換えられます。
以下のように?を用いるコードの書き方を強く推奨します。
Book.where("title = ?", params[:title])
以下のように文字列で式展開#{}を使う書き方は危険であり、避ける必要があります。
Book.where("title = #{params[:title]}")
条件文字列の中に変数を直接置くと、その変数はデータベースにそのまま渡されてしまいます。これは、悪意のある人物がエスケープされていない危険な変数を渡すことが可能になるということです。このようなコードがあると、悪意のある人物がデータベースを意のままにすることができ、データベース全体が危険にさらされます。くれぐれも、条件文字列の中に引数を直接置くことはしないでください。
疑問符(?)をパラメータで置き換えるスタイルと同様、条件中でキーバリューのハッシュも渡せます。ここで渡されたハッシュは、条件中の対応するキーバリューの部分に置き換えられます。
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
このように書くことで、条件で多数の変数を使うコードが読みやすくなります。
Active Recordは条件をハッシュで渡すこともできます。この書式を使うことで条件構文が読みやすくなります。条件をハッシュで渡す場合、ハッシュのキーには条件付けしたいフィールドを、ハッシュの値にはそのフィールドをどのように条件づけするかを、それぞれ指定します。
ハッシュによる条件を利用できるのは、等値、範囲、サブセットのチェックだけです。
Book.where(out_of_print: true)
これは以下のようなSQLを生成します。
SELECT * FROM books WHERE (books.out_of_print = 1)
フィールド名は文字列形式にもできます。
Book.where('out_of_print' => true)
belongs_toリレーションシップの場合、Active Recordオブジェクトが値として使われていれば、モデルを指定する時に関連付けキーを利用できます。この方法はポリモーフィックリレーションシップでも同様に利用できます。
author = Author.first
Book.where(author: author)
Author.joins(:books).where(books: { author: author })
Book.where(created_at: (Time.now.midnight - 1.day)..Time.now.midnight)
上の例では、昨日作成されたすべてのクライアントを検索します。内部ではSQLのBETWEEN文が使われます。
SELECT * FROM books WHERE (books.created_at BETWEEN '2008-12-21 00:00:00' AND '2008-12-22 00:00:00')
条件を配列で表すでは、さらに簡潔な文例をご紹介しています。
Rubyの終端/始端を持たない範囲オブジェクト(beginless/endless range)がサポートされており、以下のように「〜より大きい」「〜より小さい」条件の構築で利用できます。
Book.where(created_at: (Time.now.midnight - 1.day)..)
上は、以下のようなSQLを生成します。
SELECT * FROM books WHERE books.created_at >= '2008-12-21 00:00:00'
SQLのNOTクエリは、where.notで表せます。
Customer.where.not(orders_count: [1,3,5])
言い換えれば、このクエリはwhereに引数を付けずに呼び出し、直後にwhere条件にnotを渡してチェインすることで生成されています。これは以下のようなSQLを出力します。
SELECT * FROM customers WHERE (customers.orders_count NOT IN (1,3,5))
2つのリレーションをまたいでOR条件を使いたい場合は、1つ目のリレーションでorメソッドを呼び出し、そのメソッドの引数に2つ目のリレーションを渡すことで実現できます。
Customer.where(last_name: 'Smith').or(Customer.where(orders_count: [1,3,5]))
SELECT * FROM customers WHERE (customers.last_name = 'Smith' OR customers.orders_count IN (1,3,5))
データベースから取り出すレコードを特定の順序で並べ替えたい場合は、orderメソッドが使えます。
たとえば、ひとかたまりのレコードを取り出し、それをテーブル内のcreated_atの昇順で並べたい場合には以下のようにします。
Book.order(:created_at)
# または
Book.order("created_at")
ASC(昇順)やDESC(降順)も指定できます。
Book.order(created_at: :desc)
# または
Book.order(created_at: :asc)
# または
Book.order("created_at DESC")
# または
Book.order("created_at ASC")
複数のフィールドを指定して並べることもできます。
Book.order(title: :asc, created_at: :desc)
# または
Book.order(:title, created_at: :desc)
# または
Book.order("title ASC, created_at DESC")
# または
Book.order("title ASC", "created_at DESC")
orderメソッドを複数回呼び出すと、続く並び順は最初の並び順に追加されていきます。
irb> Book.order("title ASC").order("created_at DESC")
# SELECT * FROM books ORDER BY title ASC, created_at DESC
多くのデータベースシステムでは、select、pluck、idsメソッドを使った結果に対してdistinctを利用して絞り込んだとき、order句で指定したフィールドがselectのリストに含まれていないとActiveRecord::StatementInvalid例外が発生します。結果から特定のフィールドを取り出す方法については、次のセクションを参照してください。
デフォルトでは、Model.findを実行すると、結果セットからすべてのフィールドが選択されます。内部的にはSQLのselect *が実行されています。
結果セットから特定のフィールドだけを取り出したい場合は、 selectメソッドが使えます。
たとえば、out_of_printカラムとisbnカラムだけを取り出したい場合は以下のようにします。
Book.select(:isbn, :out_of_print)
# または
Book.select("isbn, out_of_print")
上の検索で実際に使われるSQL文は以下のようになります。
SELECT isbn, out_of_print FROM books
selectを使うと、選択したフィールドだけを使ってモデルオブジェクトが初期化されるため、注意が必要です。モデルオブジェクトの初期化時に指定しなかったフィールドにアクセスしようとすると、以下のメッセージが表示されます。
ActiveModel::MissingAttributeError: missing attribute: <属性名>
<属性名>は、アクセスしようとした属性です。idメソッドは、このActiveRecord::MissingAttributeErrorを発生しません。このため、関連付けを扱う場合にはご注意ください。関連付けが正常に動作するにはidメソッドが必要です。
特定のフィールドについて、重複のない一意の値を1レコードだけ取り出したい場合は、 distinctが使えます。
Customer.select(:last_name).distinct
上のコードを実行すると、以下のようなSQLが生成されます。
SELECT DISTINCT last_name FROM customers
一意性の制約を外すこともできます。
# 一意のlast_namesを返す
query = Customer.select(:last_name).distinct
# 重複の有無を問わず、すべてのlast_namesを返す
query.distinct(false)
Model.findで実行されるSQLにLIMITを適用したい場合は、リレーションでlimitメソッドやoffsetメソッドを用いてLIMITを指定できます。
limitメソッドは、取り出すレコード数の上限を指定します。offsetは、レコードを返す前にスキップするレコード数を指定します。
上を実行すると顧客が最大で5人返されます。オフセットは指定されていないので、最初の5つがテーブルから取り出されます。この時実行されるSQLは以下のような感じになります。
SELECT * FROM customers LIMIT 5
offsetを追加すると以下のようになります。
Customer.limit(5).offset(30)
上のコードは、顧客の最初の30人をスキップして31人目から最大5人の顧客を返します。このときのSQLは以下のようになります。
SELECT * FROM customers LIMIT 5 OFFSET 30
検索メソッドで実行されるSQLにGROUP BY句を追加したい場合は、groupメソッドを検索メソッドに追加できます。
たとえば、注文(order)の作成日のコレクションを検索したい場合は、以下のようにします。
Order.select("created_at").group("created_at")
上のコードは、データベースで注文のある日付ごとにOrderオブジェクトを1つ作成します。
上で実行されるSQLは以下のようなものになります。
SELECT created_at
FROM orders
GROUP BY created_at
グループ化した項目の合計を1つのクエリで得るには、groupの次にcountを呼び出します。
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
上で実行されるSQLは以下のようなものになります。
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
SQLでは、GROUP BYフィールドで条件を指定する場合にHAVING句を使います。検索メソッドでhavingメソッドを使えば、Model.findで生成されるSQLにHAVING句を追加できます。
以下に例を示します。
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
上で実行されるSQLは以下のようになります。
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
これはorderオブジェクトごとに注文日と合計金額を返します。具体的には、priceが$200を超えている注文が、dateごとにまとめられて返されます。
orderオブジェクトごとのtotal_priceにアクセスするには以下のように書きます。
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# 最初のOrderオブジェクトの合計額が返される
unscopeで特定の条件を取り除けます。以下に例を示します。
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
上で実行されるSQLは以下のようなものになります。
SELECT * FROM books WHERE id > 100 LIMIT 20
-- `unscope`する前のオリジナルのクエリ
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
以下のように特定のwhere句でunscopeを指定することも可能です。
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
unscopeをリレーションに適用すると、それにマージされるすべてのリレーションにも影響します。
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
以下のようにonlyメソッドを使って条件を上書きできます。
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
上で実行されるSQLは以下のようになります。
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- `only`を使う前のオリジナルのクエリ
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
reselectメソッドで以下のように既存のselect文を上書きできます。
Book.select(:title, :isbn).reselect(:created_at)
上で実行されるSQLは以下のようになります。
SELECT books.created_at FROM books
reselect句を使わない場合と比較してみましょう。
Book.select(:title, :isbn).select(:created_at)
上で実行されるSQLは以下のようになります。
SELECT books.title, books.isbn, books.created_at FROM books
reorderメソッドは、以下のようにデフォルトのスコープの並び順を上書きします。
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
続いて以下を実行します。
上で実行されるSQLは以下のようになります。
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
reorderを使うと、以下のようにbooksで別の並び順を指定できます。
Author.find(10).books.reorder('year_published ASC')
上で実行されるSQLは以下のようになります。
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
reverse_orderメソッドは、並び順が指定されている場合に並び順を逆にします。
Book.where("author_id > 10").order(:year_published).reverse_order
上で実行されるSQLは以下のようになります。
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
SQLクエリで並び順を指定する句がない状態でreverse_orderを実行すると、主キーの逆順になります。
Book.where("author_id > 10").reverse_order
上で実行されるSQLは以下のようになります。
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
このメソッドは引数を取りません。
rewhereメソッドは、以下のように既存のwhere条件を上書きします。
Book.where(out_of_print: true).rewhere(out_of_print: false)
上で実行されるSQLは以下のようになります。
SELECT * FROM books WHERE out_of_print = 0
rewhere句ではなくwhere句にすると、2つのwhere句のAND条件になります。
Book.where(out_of_print: true).where(out_of_print: false)
上で実行されるSQLは以下のようになります。
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
noneメソッドは、チェイン(chain)可能なリレーションを返します(レコードは返しません)。このメソッドから返されたリレーションにどのような条件をチェインさせても、常に空のリレーションが生成されます。これは、メソッドまたはスコープへのチェイン可能な応答が必要で、しかも結果を一切返したくない場合に便利です。
Book.none # 空のリレーションを返し、クエリを生成しない
# highlighted_reviewsメソッドはリレーションを返すことが期待されている
Book.first.highlighted_reviews.average(:rating)
# => 本1冊あたりの平均レーティングを返す
class Book
# レビューが5件以上の場合にレビューを返す
# それ以外の本はレビューなしとみなす
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # レビュー5件未満の場合
end
end
end
Active Recordには、返されたどのオブジェクトに対しても変更を明示的に禁止するreadonlyメソッドがあります。読み取り専用を指定されたオブジェクトに対する変更の試みはすべて失敗し、ActiveRecord::ReadOnlyRecord例外が発生します。
customer = Customer.readonly.first
customer.visits += 1
customer.save
上のコードでは customerに対して明示的にreadonlyが指定されているため、visitsの値を更新して customer.saveを行なうとActiveRecord::ReadOnlyRecord例外が発生します。
ロックは、データベースのレコードを更新する際の競合状態を避け、アトミックな (=中途半端な状態のない) 更新を行なうために有用です。
Active Recordには2とおりのロック機構があります。
- 楽観的ロック(optimistic)
- 悲観的ロック(pessimistic)
楽観的ロックでは、複数のユーザーが同じレコードを同時編集することを許し、データの衝突が最小限であることを仮定しています。この方法では、レコードがオープンされてから変更されたことがあるかどうかをチェックします。そのような変更が行われ、かつ更新が無視された場合、ActiveRecord::StaleObjectError例外が発生します。
楽観的ロックカラム
楽観的ロックを使うには、テーブルにlock_versionという名前のinteger型カラムが必要です。Active Recordは、レコードが更新されるたびにlock_versionカラムの値を1ずつ増やします。更新リクエストが発生したときのlock_versionの値がデータベース上のlock_versionカラムの値よりも小さい場合、更新リクエストは失敗し、以下のようにActiveRecord::StaleObjectErrorエラーが発生します。
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # ActiveRecord::StaleObjectErrorが発生
開発者は、例外の発生後にこの例外をrescueして衝突を解決する必要があります。衝突の解決方法は、ロールバック、マージ、またはビジネスロジックに応じた解決方法のいずれかをお使いください。
ActiveRecord::Base.lock_optimistically = falseを設定するとこの動作をオフにできます。
ActiveRecord::Baseには、lock_versionカラム名を上書きするためのlocking_column属性が用意されています。
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
悲観的ロックでは、データベースが提供するロック機構を利用します。リレーションの構築時にlockを使うと、選択した行に対する排他的ロックを取得できます。lockを用いているリレーションは、デッドロック条件を回避するために通常トランザクションの内側にラップされます。
以下に例を示します。
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, second edition'
book.save!
end
バックエンドがMySQLの場合、上のセッションによって以下のSQLが生成されます。
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, second edition' WHERE id = 1
SQL (0.8ms) COMMIT
異なる種類のロックを使いたい場合は、lockメソッドに生SQLを渡すことも可能です。たとえば、MySQLにはLOCK IN SHARE MODEという式があります(レコードのロック中にも他のクエリからの読み出しを許可します)。この式を指定するには、以下のように単にlockオプションの引数で渡します。
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
この機能を使うには、lockメソッドで渡す生SQLがデータベースでサポートされていなければなりません。
モデルのインスタンスが既にある場合は、トランザクションを開始してその中でロックを一度に取得できます。
book = Book.first
book.with_lock do
# このブロックはトランザクション内で呼び出される
# bookはロック済み
book.increment!(:views)
end
Active Recordは JOIN句のSQLを具体的に指定する2つの検索メソッドを提供しています。1つはjoins、もう1つはleft_outer_joinsです。joinsメソッドはINNER JOINやカスタムクエリに使われ、left_outer_joinsはLEFT OUTER JOINクエリの生成に使われます。
joinsメソッドには複数の使い方があります。
joinsメソッドの引数に生のSQLを指定することでJOIN句を指定できます。
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
これによって以下のSQLが生成されます。
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
Active Recordでは、joinsメソッドを利用して関連付けでJOIN句を指定する際に、モデルで定義されている関連付け名をショートカットとして利用できます(詳しくはActive Recordの関連付けを参照)。
以下のすべてにおいて、INNER JOINによる結合クエリが期待どおりに生成されます。
上によって以下が生成されます。
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
上のSQLを日本語で書くと「レビュー付きのすべての本について、Bookオブジェクトを1つ返す」となります。本1冊にレビューが1件以上ついている場合は、本が重複表示される点にご注意ください。重複のない一意の本を表示したい場合は、Book.joins(:reviews).distinctが使えます。
Book.joins(:author, :reviews)
上によって以下が生成されます。
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
上のSQLを日本語で書くと「著者があり、レビューが1件以上ついている本をすべて表示する」となります。これも上と同様に、レビューが複数ある本は複数回表示されます。
Book.joins(reviews: :customer)
上によって以下が生成されます。
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
上のSQLを日本語で書くと「ある顧客によるレビューが付いている本をすべて返す」となります。
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier] )
上によって以下が生成されます。
SELECT * FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
上のSQLを日本語で書くと「レビューが付いていて、かつ、ある顧客が注文した本のすべての著者と、それらの本の仕入先(suppliers)を返す」となります。
標準の配列および文字列条件を使って、結合テーブルに条件を指定できます。ハッシュ条件の場合は、結合テーブルで条件を指定するときに特殊な構文を使います。
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
上は、created_atをSQLのBETWEEN式で比較することで、昨日注文を行ったすべての顧客を検索できます。
さらに読みやすい別の方法は、以下のようにハッシュ条件をネストさせることです。
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
さらに高度な条件指定や既存の名前付きスコープの再利用を行いたい場合は、mergeが利用できるでしょう。最初に、Orderモデルに新しい名前付きスコープを追加してみましょう。
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
これで、created_in_time_rangeスコープ内でmergeを用いてマージできるようになります。
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
上も、SQLのBETWEEN式で比較することで、昨日注文を行ったすべての顧客を検索できます。
関連レコードがあるかどうかにかかわらずレコードのセットを取得したい場合は、left_outer_joins メソッドを使います。
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
上のコードは、以下のクエリを生成します。
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
上のSQLを日本語で書くと「すべての顧客を返すとともに、それらの顧客がレビューを付けていればレビュー数を返し、レビューを付けていない場合はレビュー数を返さない」となります。
eager loading(一括読み込み)とは、Model.findによって返されるオブジェクトに関連付けられたレコードを、クエリの利用回数をできるかぎり減らして読み込むためのメカニズムです。
N + 1クエリ問題
以下のコードについて考えてみましょう。このコードは、本を10冊検索して著者のlast_nameを表示します。
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
このコードは一見何の問題もないように見えます。しかし本当の問題は、実行されたクエリの回数が無駄に多いことなのです。上のコードでは、最初に本を10冊検検索するクエリを1回発行し、次にそこからlast_nameを取り出すのにクエリを10回発行しますので、合計で 11 回のクエリが発行されます。
N + 1クエリ問題を解決する
Active Recordでは、以下のメソッドを用いることで、読み込まれるすべての関連付けを事前に指定できます。これは、Model.find呼び出しのincludesメソッドを指定することでできます。includesを指定すると、Active Recordは指定されたすべての関連付けを最小限のクエリ回数で読み込むようになります。
上の例で言うと、Book.limit(10)というコードを以下のように書き直すことで、last_nameが一括で読み込まれます。
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
最初の例では 11 回もクエリが実行されましたが、書き直した例ではわずか 2 回にまで減りました。
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
Active Recordは、1つのModel.find呼び出しで関連付けをいくつでもeager loadingできます。これを行なうには、includesメソッドを呼び出して「配列」「ハッシュ」または「配列やハッシュをネストしたハッシュ」を指定します。
Customer.includes(:orders, :reviews)
上のコードは、すべての顧客を表示するとともに、顧客ごとに関連付けられている注文やレビューも表示します。
Customer.includes(orders: {books: [:supplier, :author]}).find(1)
上のコードは、id=1の顧客を検索し、関連付けられたすべての注文、それぞれの本の仕入先と著者を読み込みます。
Active Recordでは、eager loadingされた関連付けに対して、joinsのように条件を指定可能ですが、このやり方よりもjoinsの使用を推奨します。
とはいえ、eager loadingされた関連付けに対して条件を指定せざるを得ない場合は、以下のように普通にwhereを使っても大丈夫です。
Author.includes(:books).where(books: { out_of_print: true })
このコードは、以下のようにLEFT OUTER JOINを含むクエリを1つ生成します。joinsメソッドを使うと、代わりにINNER JOINを使うクエリが生成されます。
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN "books" ON "books"."author_id" = "authors"."id" WHERE (books.out_of_print = 1)
where条件がない場合は、通常のクエリが2つ生成されます。
whereがこのように動作するのは、ハッシュを渡した場合だけです。SQLフラグメント文字列を渡す場合には、強制的に結合テーブルとして扱うために referencesを使う必要があります。
Author.includes(:books).where("books.out_of_print = true").references(:books)
このincludesクエリの場合、どの著者にも本がないので、すべての著者が引き続き読み込まれます。joins(INNER JOIN)を使う場合、結合条件は必ずマッチ しなければならず 、それ以外の場合にはレコードは返されません。
関連付けがjoinの一部としてeager loadingされている場合、読み込んだモデルの中にカスタマイズされたselect句のフィールドが存在しなくなります。これは親レコード(または子レコード)の中で表示してよいかどうかが曖昧になってしまうためです。
よく使うクエリをスコープに設定すると、関連オブジェクトやモデルへのメソッド呼び出しとして参照できるようになります。スコープでは、where、joins、includesなど、これまでに登場したメソッドをすべて使えます。どのスコープメソッドも、常にActiveRecord::Relationオブジェクトを返します。スコープの本体では、別のスコープなどのメソッドをスコープ上で呼び出せるようにするため、ActiveRecord::Relationかnilのいずれかを返すようにすべきです。
シンプルなスコープを設定するには、以下のようにクラスの内部にscopeメソッドを書き、スコープが呼び出されたときに実行したいクエリをそこで渡します。
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
作成したout_of_printスコープは、以下のようにクラスメソッドとして呼び出せます。
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # all out of print books
あるいは、以下のようにBookオブジェクトを用いる関連付けでも呼び出せます。
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # all out of print books by `author`
スコープは、以下のようにスコープ内でチェインすることも可能です。
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
スコープには以下のように引数を渡せます。
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
引数付きスコープの呼び出しは、クラスメソッドの呼び出しと同様です。
irb> Book.costs_more_than(100.10)
ただし、スコープに引数を渡す機能は、クラスメソッドによって提供される機能を単に複製したものです。
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
スコープとして定義したメソッドは、関連付けオブジェクトからもアクセス可能です。
irb> author.books.costs_more_than(100.10)
スコープで条件文を使うことも可能です。
class Order < ApplicationRecord
scope :created_before, ->(time) { where("created_at < ?", time) if time.present? }
end
他の例と同様、これもクラスメソッドのように振る舞います。
class Order < ApplicationRecord
def self.created_before(time)
where("created_at < ?", time) if time.present?
end
end
ただし、1つ重要な注意点があります。条件文を評価した結果がfalseになった場合であっても、スコープは常にActiveRecord::Relationオブジェクトを返します。クラスメソッドの場合はnilを返すので、この点において振る舞いが異なります。したがって、条件文を使うクラスメソッドをチェインし、かつ、条件文のいずれかがfalseを返す場合、NoMethodErrorを発生する可能性があります。
あるスコープをモデルのすべてのクエリに適用したい場合、モデル自身の内部でdefault_scopeメソッドを使えます。
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
このモデルに対してクエリが実行されたときのSQLクエリは以下のような感じになります。
SELECT * FROM books WHERE (out_of_print = false)
デフォルトスコープの条件が複雑になる場合は、以下のようにスコープをクラスメソッドとして定義してもよいでしょう。
class Book < ApplicationRecord
def self.default_scope
# ActiveRecord::Relationを返すべき
end
end
スコープの引数がHashで与えられると、レコードを作成するときにdefault_scopeも適用されます。ただし、レコードを更新する場合は適用されません。例:
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
引数にArrayが与えられた場合は、default_scopeクエリの引数はHashのデフォルト値に変換されない点に注意が必要です。例:
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
where句と同様、スコープもAND条件でマージできます。
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where('year_published >= ?', Date.current.year - 50 )}
scope :old, -> { where('year_published < ?', Date.current.year - 50 )}
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
scopeとwhere条件を混用してマッチさせることが可能です。このとき生成される最終的なSQLでは、以下のようにすべての条件がANDで結合されます。
irb> Book.in_print.where('price < 100')
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
末尾のwhere句をどうしてもスコープより優先したい場合は、mergeが使えます。
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
ただし、1つ重要な注意点があります。default_scopeで定義した条件は、以下のようにscopeやwhereで定義した条件よりも前に配置されます。
class Book < ApplicationRecord
default_scope { where('year_published >= ?', Date.current.year - 50 )}
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
end
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
上の例でわかるように、default_scopeの条件は、scopeとwhereの条件よりも前に配置されています。
何らかの理由でスコープをすべて解除したい場合はunscopedメソッドが使えます。このメソッドは、モデルで指定されているdefault_scopeを適用したくないクエリがある場合に特に便利です。
このメソッドはスコープをすべて解除し、テーブルに対して通常の (スコープなしの) クエリを実行するようにします。
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscoped はブロックも受け取れます。
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
Active Recordは、テーブルに定義されるすべてのフィールド(属性とも呼ばれます)に対して自動的に検索メソッドを提供します。たとえば、Customerモデルにfirst_nameというフィールドがあると、find_by_first_nameというメソッドがActive Recordによって自動的に作成されます。Customerモデルにlockedというフィールドがあれば、find_by_lockedというメソッドを利用できるようになります。
この動的検索メソッドの末尾にCustomer.find_by_first_name!("Ryan")のように感嘆符 (!) を追加すると、該当するレコードがない場合にActiveRecord::RecordNotFoundエラーが発生するようになります。
first_nameとorders_countを両方検索したい場合は、2つのフィールド名を_and_でつなぐだけでメソッドを利用できるようになります。たとえば、Customer.find_by_first_name_and_orders_count("Ryan", 5)といった書き方が可能です。
enumを使うと、属性で使う値を配列で定義して名前で参照できるようになります。enumがデータベースに実際に保存されるときは、値に対応する整数値が保存されます。
enumを宣言すると、enumのすべての値について以下が作成されます。
- enum値のいずれかの値を持つ(またはもたない)すべてのオブジェクトの検索に利用可能なスコープが作成される
- あるオブジェクトがenumの特定の値を持つかどうかを判定できるインスタンスメソッドを作成する
- あるオブジェクトのenum値を変更するインスタンスメソッドを作成する
たとえば以下のenum宣言があるとします。
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
このときstatus enumのスコープが自動的に作成され、以下のようにstatusの特定の値を持つ(または持たない)すべてのオブジェクトを検索できるようになります。
irb> Order.shipped
=> #<ActiveRecord::Relation> # all orders with status == :shipped
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # all orders with status != :shipped
以下の?付きインスタンスメソッドは自動で作成されます。以下のようにモデルがstatus enumの値を持っているかどうかをtrue/falseで返します。
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
以下の!付きインスタンスメソッドは自動で作成されます。最初にstatusの値を更新し、次にstatusがその値に設定されたかどうかをtrue/falseで返します。
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
enumの完全なドキュメントについてはActiveRecord::Enumを参照してください。
Active Record パターンには メソッドチェイン (Method chaining - Wikipedia) が実装されています。これにより、複数のActive Recordメソッドをシンプルな方法で次々に適用できるようになります。
文中でメソッドチェインを利用できるのは、その前のメソッドがActiveRecord::Relation (all、where、joinsなど) を1つ返す場合です。単一のオブジェクトを返すメソッド (単一のオブジェクトを取り出すを参照) は文の末尾に置かなければなりません。
いくつか例をご紹介します。本ガイドでは一部の例のみをご紹介し、すべての例を網羅することはしません。Active Recordメソッドが呼び出されると、クエリはその時点ではすぐには生成されず、データベースへの送信もされません。クエリは、データが実際に必要になった時点で初めて生成され送信されます。したがって、以下のそれぞれの例で生成されるクエリはそれぞれ1つのみです。
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
上のコードから以下のようなSQLが生成されます。
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
上のコードから以下のようなSQLが生成されます。
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
1つのクエリが複数のレコードとマッチする場合、find_byは「最初」の結果だけを返し、他は返しません(上のLIMIT 1 文を参照)。
レコードを検索し、レコードがなければ作成するという連続処理はよく行われます。find_or_create_byおよびfind_or_create_by!メソッドを使えば、これらの処理を一度に行なえます。
find_or_create_byメソッドは、指定された属性を持つレコードが存在するかどうかをチェックします。レコードがない場合はcreateが呼び出されます。以下の例を見てみましょう。
'Andy'という名前の顧客を探し、いなければ作成したいとします。これを行なうには以下を実行します。
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
このメソッドによって生成されるSQLは以下のようになります。
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_byは、既にあるレコードか新しいレコードのいずれかを返します。上の例の場合、Andyという名前の顧客がなかったのでレコードを作成して返しました。
createなどと同様、バリデーションがパスするかどうかによって、新しいレコードがデータベースに保存されていない可能性があります。
今度は、新しいレコードを作成するときにlocked属性をfalseに設定したいが、それをクエリに含めたくないとします。そこで、"Andy"という名前の顧客を検索するか、その名前の顧客がいない場合は"Andy"というクライアントを作成してロックを外すことにします。
これは2とおりの方法で実装できます。1つ目はcreate_withを使う方法です。
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
2つ目はブロックを使う方法です。
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
このブロックは、顧客が作成されるときにだけ実行されます。このコードを再度実行すると、このブロックは実行されません。
find_or_create_by!を使うと、新しいレコードが無効な場合に例外を発生するようになります。バリデーション(検証)については本ガイドでは解説していませんが、たとえば以下のバリデーションをCustomerモデルに追加したとします。
validates :orders_count, presence: true
orders_countを指定せずに新しいCustomerモデルを作成しようとすると、レコードは無効になって以下のように例外が発生します。
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can't be blank
find_or_initialize_byメソッドはfind_or_create_byと同様に動作しますが、createの代わりにnewを呼ぶ点が異なります。つまり、モデルの新しいインスタンスは作成されますが、その時点ではデータベースに保存されていません。find_or_create_byの例を少し変えて説明を続けます。今度は'Nina'という名前の顧客が必要だとします。
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
オブジェクトはまだデータベースに保存されていないため、生成されるSQLは以下のようなものになります。
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
このオブジェクトをデータベースに保存したい場合は、単にsaveを呼び出します。
独自のSQLでレコードを検索したい場合は、find_by_sqlメソッドが使えます。このfind_by_sqlメソッドは、オブジェクトの配列を1つ返します。クエリがレコードを1つしか返さなかった場合にも配列が返されますのでご注意ください。たとえば、以下のクエリを実行したとします。
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sqlは、カスタマイズしたデータベース呼び出しを簡単な方法で提供し、インスタンス化されたオブジェクトを返します。
find_by_sqlはconnection.select_allと深い関係があります。select_allはfind_by_sqlと同様、カスタムSQLを用いてデータベースからオブジェクトを取り出しますが、取り出したオブジェクトをインスタンス化しない点が異なります。このメソッドはActiveRecord::Resultクラスのインスタンスを1つ返します。このオブジェクトでto_aを呼ぶと、各レコードに対応するハッシュを含む配列を1つ返します。
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
pluckは、1つのモデルで使われているテーブルから1つ以上のカラムを取得するクエリを送信するときに利用できます。引数としてカラム名のリストを与えると、指定したカラムの値の配列を、対応するデータ型で返します。
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluckを使えば、以下のようなコードをシンプルなものに置き換えられます。
Customer.select(:id).map { |c| c.id }
# または
Customer.select(:id).map(&:id)
# または
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
上は以下に置き換えられます。
Customer.pluck(:id)
# または
Customer.pluck(:id, :first_name)
selectと異なり、pluckはデータベースから受け取った結果を直接Rubyの配列に変換してくれます。そのためのActiveRecordオブジェクトを事前に構成しておく必要はありません。従って、このメソッドは大規模なクエリや利用頻度の高いクエリで使うとパフォーマンスが向上します。ただし、オーバーライドを行なうモデルメソッドは使えません。以下に例を示します。
class Customer < ApplicationRecord
def name
"私は#{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["私はDavid", "私はJeremy", "私はJose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
単一テーブルのフィールド読み出しに加えて、複数のテーブルでも同じことができます。
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
さらにpluckは、selectなどのRelationスコープと異なり、クエリを直接トリガするので、その後ろに他のスコープをチェインできません。ただし、構成済みのスコープをpluckの前に置くことは可能です。
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
知っておくと良い注意点は、リレーションオブジェクトにincludesがあると、eager loadingが不必要なクエリにおいてでも、pluckがeager loadingを引き起こすことです。以下に例を示します。
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
これを回避する方法の1つは、以下のようにincludesをunscopeすることです。
irb> assoc.unscope(:includes).pluck(:id)
idsは、テーブルの主キーを使っているリレーションのIDをすべて取り出すのに使えます。
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
オブジェクトが存在するかどうかをチェックするにはexists?メソッドを使います。このメソッドは、findと同様のクエリを使ってデータベースにクエリを送信しますが、オブジェクトのコレクションではなくtrueまたはfalseを返します。
exists?の引数には複数の値を渡せます。ただし、それらの値のうち1つでも存在していれば、他の値が存在していなくてもtrueを返します。
Customer.exists?(id: [1,2,3])
# または
Customer.exists?(first_name: ['Jane', 'Sergei'])
exists?メソッドは、引数なしでモデルやリレーションに使うことも可能です。
Customer.where(first_name: 'Ryan').exists?
上の例では、first_nameが'Ryan'のクライアントが1人でもいればtrueを返し、それ以外の場合はfalseを返します。
上の例では、Customerテーブルが空ならfalseを返し、それ以外の場合はtrueを返します。
モデルやリレーションでの存在チェックにはany?やmany?も使えます。many?はSQLのCOUNTで存在をチェックします。
# モデル経由
Order.any?
# => SELECT 1 FROM orders LIMIT 1
Order.many?
# => SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
# 名前付きスコープ経由
Order.shipped.any?
# => SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
# => SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
# リレーション経由
Book.where(out_of_print: true).any?
Book.where(out_of_print: true).many?
# 関連付け経由
Customer.first.orders.any?
Customer.first.orders.many?
このセクションでは冒頭でcountメソッドを例に説明していますが、ここで説明されているオプションは以下のすべてのサブセクションにも該当します。
あらゆる計算メソッドは、モデルに対して直接実行できます。
irb> Customer.count
SELECT COUNT(*) FROM customers
リレーションに対しても直接実行できます。
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
この他にも、リレーションに対してさまざまな検索メソッドを利用して複雑な計算を行なえます。
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
上のコードは以下を実行します。
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
モデルのテーブルに含まれるレコードの個数を数えるにはCustomer.countが使えます。返されるのはレコードの個数です。肩書きを指定して顧客の数を数えるときはCustomer.count(:title)と書けます。
オプションについては、1つ上の計算セクションを参照してください。
テーブルに含まれる特定の数値の平均を得るには、そのテーブルを持つクラスでaverageメソッドを呼び出します。このメソッド呼び出しは以下のようになります。
Order.average("subtotal")
返される値は、そのフィールドの平均値です。通常3.14159265のような浮動小数点になります。
オプションについては、1つ上の計算セクションを参照してください。
テーブルに含まれるフィールドの最小値を得るには、そのテーブルを持つクラスでminimumメソッドを呼び出します。このメソッド呼び出しは以下のようになります。
Order.minimum("subtotal")
オプションについては、1つ上の計算セクションを参照してください。
テーブルに含まれるフィールドの最大値を得るには、そのテーブルを持つクラスに対してmaximumメソッドを呼び出します。このメソッド呼び出しは以下のようになります。
Order.maximum("subtotal")
オプションについては、1つ上の計算セクションを参照してください。
テーブルに含まれるフィールドのすべてのレコードにおける合計を得るには、そのテーブルを持つクラスに対してsumメソッドを呼び出します。このメソッド呼び出しは以下のようになります。
オプションについては、1つ上の計算セクションを参照してください。
リレーションではexplainを実行できます。EXPLAINの出力はデータベースによって異なります。
Customer.where(id: 1).joins(:orders).explain
上では以下のような結果が生成されます。
EXPLAIN for: SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
上の結果はMySQLおよびMariaDBの場合です。
Active Recordは、対応するデータベースシェルの出力をエミュレーションして整形します。同じクエリをPostgreSQLアダプタで実行すると、以下のような結果が得られます。
EXPLAIN for: SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
eager loadingを使用している場合、内部的には複数のクエリがトリガされることがあり、このとき一部のクエリが先行するクエリの結果を必要とすることがあります。このためexplainは、このクエリを実際に実行した後で、クエリプランを要求します。以下に例を示します。
Customer.where(id: 1).includes(:orders).explain
MySQLとMariaDBでは以下の結果を生成します。
EXPLAIN for: SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN for: SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
PostgreSQLの場合は以下のような結果を生成します。
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN for: SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
EXPLAINの出力を解釈することは、本ガイドの範疇を超えます。
以下の情報を参考にしてください。
🖋 GitHubで編集を提案する
/
📕 英語で読む
Railsガイドは GitHub の yasslab/railsguides.jp で管理・公開されております。本ガイドを読んで気になる文章や間違ったコードを見かけたら、気軽に Pull Request を出して頂けると嬉しいです。Pull Request の送り方については GitHub の README をご参照ください。
原著における間違いを見つけたら『Rails のドキュメントに貢献する』を参考にしながらぜひ Rails コミュニティに貢献してみてください 🛠💨✨
本ガイドの品質向上に向けて、皆さまのご協力が得られれば嬉しいです。
Railsガイド運営チーム (@RailsGuidesJP)

Railsガイドは下記の協賛企業から継続的な支援を受けています。もしご興味あれば、協賛プランから気軽にお問い合わせいただけると嬉しいです。
- Star
-

-

